Vsebina
- Zgodovina stvarjenja
- Razumevanje in razvrščanje podatkovnih zbirk
- Modeli elektronske obdelave
- Glavne razlike v podatkovnih zbirkah
- Sistemi za upravljanje DBMS
- Razvrstitev funkcij in zahtev
- Funkcija
- Namen
- Hierarhični model
- Grafično usmerjen DMS
- Skalabilnost shranjevanja
- Prednosti in slabosti
- Aplikacije
- prihodnji trendi
Podatkovna baza je niz podatkov, ki jih je treba organizirati, sistem za upravljanje podatkovnih baz (DBMS) pa je odgovoren za njeno upravljanje, torej za določanje strukture, vrstnega reda, pravic dostopa in odvisnosti. V ta namen se uporabljata lasten prevajalnik in ustrezen model, ki opredeljuje arhitekturo sistema podatkovne zbirke. Arhitektura se uporablja za razvrščanje podatkovnih zbirk.
Zgodovina stvarjenja
Podatkovne zbirke (DB) so Logično strukturirani sistemi za elektronsko upravljanje, ki se izvaja s sistemom za upravljanje podatkovnih zbirk (DBMS) z dodajanjem v repozitorij. Večino podatkovnih zbirk je mogoče odpreti, urejati in pregledovati le s posebnimi aplikacijami. DB se razvrščajo v skladu z naslednjimi načeli. V šestdesetih letih prejšnjega stoletja se je začel razvijati koncept elektronske informacijske baze kot ločene plasti programske opreme med operacijskim sistemom in aplikacijskim programom.
Zamisel o sistemu elektronske zbirke podatkov je bila ena najpomembnejših inovacij v razvoju računalnikov. Prvi razviti modeli so bili hierarhične in mrežne zbirke podatkov. IBM je v sedemdesetih letih z razvojem relacijskega modela podatkovne baze povzročil revolucijo na tem področju. Najuspešnejši izdelki v tistem času so bili Oraclov poizvedovalni jezik za podatkovne zbirke SQL ter IBM-ova naslednika, SQL/DS in DB2.
Razumevanje in razvrščanje podatkovnih zbirk
Danes so sistemi podatkovnih baz pomembni v številnih znanstvenih, tehničnih in uporabniških aplikacijah. Katera koli vrsta programska oprema, Razvit za podjetja, ki temelji na robustnih podatkovnih bazah s številnimi možnostmi in orodji za sistemski administratorji. Vse pomembnejša je tudi varnost podatkov, saj elektronske zbirke podatkov hranijo in šifrirajo gesla, osebne podatke in celo elektronske valute.
Sodobni finančni sistem ni nič drugega kot omrežje podatkovnih baz, v katerem velik del denarja obstaja le v obliki elektronskih informacijskih enot, katerih zaščita z varno podatkovno bazo je eden glavnih ciljev finančnih institucij.

Glede na spremenljivost podatkovne zbirke se njena vrsta deli na statično ali dinamično.
Statične funkcije zbirke podatkov:
- Dovolite samo branje podatkov, ne pa tudi spreminjanja.
- Uporabljajo se za biografije in zgodovinska dejstva ali scenarije, do katerih je mogoče dostopati za raziskave, ne da bi bilo treba spreminjati vsebino.
- Ko so povezani v omrežje, so varni in enostavni za uporabo.
Funkcije dinamičnih podatkovnih zbirk:
- Imajo predstavo o samoupravljanju.
- Lahko je povezan z dinamičnimi omrežji.
- Ta strukturna povezava omogoča shranjevanje in posodabljanje podatkov iz zbirke podatkov.
- Kot jezik povezave med omrežjem in dinamično podatkovno zbirko uporablja HTML.
- Najpogosteje uporabljen jeziki za Dinamično omrežje, povezano z BBDD: Perl, CGI, PHP, JSP in ASP.
Glavne DBMS, ki upravljajo dinamične spletne strani, so PostgresQL, MySQL, Oracle in Microsoft SQL.
Za razumevanje možnosti razvrščanja podatkovnih zbirk, ki se uporabljajo v akademskih in izobraževalnih okoljih, upoštevajte:
- bibliografski;
- dokumentarni film;
- Specializirano;
- vodila.
Funkcionalnost bibliografskih podatkovnih zbirk:
- Povezava s starimi zapisi, ki vsebujejo informacije o lokaciji knjige ali dokumenta.
- Ne vsebujejo celotnega besedila, temveč le sklic.
- zaradi formatov, kot je PDF, omogoča dostop do izvirnih člankov, na katere se sklicuje.
- z razvojem tehnologije vključite povezave iz drugih medijev.
Specializirane funkcije BBDD:
- Vsebuje natančne informacije in je usmerjen v določeno temo.
- Uporablja se v akademskih in znanstvenih okoljih.
- Za nekatere primere se ne upošteva Kako ga pravilno izvesti BBDD: npr. telefonski imenik, seznam kontaktov podjetja ali mednarodnega podjetja.
Modeli elektronske obdelave
Če želite podrobno raziskati vprašanje, kakšne so možnosti razvrščanja podatkovnih zbirk, se ne morete izogniti temi modelov. Hierarhične podatkovne zbirke je v 60. letih prejšnjega stoletja prvi razvil Hollerith; temeljile so na tipu shranjevanja 1N/ NN v obliki obrnjenega drevesa.
Razmerja so tipa 1N, pri čemer ima lahko nadrejeno vozlišče več podrejenih vozlišč, podrejeno vozlišče pa ne more pripadati več kot enemu nadrejenemu vozlišču. Njihova pomanjkljivost je, da redundanca podatkov ni dobro predstavljena.
Model omrežja podatkovnih baz, ki ga je predlagal CODASYL, je njegov prvi sistem za upravljanje (IMS), ki se je pojavil leta 1968 za program NASA "Apollo". Rešil je nekatere težave prejšnjega hierarhičnega modela, ki se v sodobni informacijski tehnologiji skorajda ne uporabljajo več.
Za razumevanje sodobnega modela je treba upoštevati, kakšno je razmerje med starševskimi in otroškimi vozlišči v klasifikaciji podatkovne zbirke. Danes se uporabljajo razmerja tipa NN, pri katerih je dovoljeno, da otroško podvozje pripada več kot enemu nadrejenemu vozlišču. Skupaj s hierarhičnim modelom tvori prvo generacijo podatkovnih zbirk.
Prednosti modela: zagotavljajo odlično stabilnost, dobro zmogljivost in boljšo redundanco obdelave. Pomanjkljivost modela je zapletenost sistema, ki zahteva znanje programiranja.
Značilnosti transakcijskih podatkovnih zbirk:
- Edini cilj je pošiljanje in sprejemanje podatkov z veliko hitrostjo.
- Namenjeni so kvalitativni analizi in pridobivanju podatkov.
- Edinstven namen je čim hitrejše zbiranje in pridobivanje podatkov, zato redundanca in podvajanje informacij nista problem, kot je to značilno za druge zbirke podatkov.
- Omogočanje povezave z relacijskimi podatkovnimi zbirkami.
- Operacije so atomične, pri tej vrsti je mogoče, da se izvedejo v celoti (celovitost) ali pa sploh ne.
Glavne razlike v podatkovnih zbirkah
Dokumentarni - vrača vsebino, dela s kognitivnimi in konceptualnimi dokumenti, pripada intelektualnemu in akademskemu okolju. Za nadzor terminologije imajo upravitelje dokumentov in vsebin, kot so CDS/ISIS, Filemaker, Knosys ali Imagic Text. Zlahka so na voljo s standardiziranimi jeziki za poizvedbe in imajo klasifikacijo podatkovnih zbirk po vrsti podatkovnega modela.
Relacijski: temelji na vzpostavljanju povezav med nizi podatkov, organiziranih v tabelah, ki izpolnjujejo nekatere osnovne zahteve. Imajo določeno število polj. Vsak atribut ima ime in več možnih vrednosti. Vsak zapis je edinstven in ga je mogoče identificirati s ključem. Izvajajo poizvedovalni jezik SQL in temeljijo na modelu, ki ga je v 70. letih prejšnjega stoletja razvil Edgar Codd.

Objektno usmerjene zbirke podatkov vračajo fizične datoteke ali programsko kodo, pojavile so se konec dvajsetega stoletja. Uporablja se v industrijski proizvodnji in oblikovanju. delo z objektno usmerjenim jezikom, kot sta C++ ali Python. Upoštevajte "zlato pravilo": obstojnost, upravitelj sekundarnega shranjevanja, sočasnost, obnovitev in objekt poizvedbe.
Sistemi za upravljanje DBMS

Sistem za upravljanje podatkovnih zbirk (DBMS) je izraz za opis funkcij in zahtev transakcij v sistemu za upravljanje podatkovnih zbirk, skrajšano ACID iz Atomicity, Consistency, Isolation and Durability (Atomičnost, doslednost, izolacija in trajnost). Ti štirje parametri pokrivajo najpomembnejše zahteve DBMS, združljive z ACID:
- Atomičnost označuje lastnost "vse ali nič" upravljavcev podatkovnih zbirk, da je poizvedba veljavna, transakcija pravilno izvedena in izvedena s pravilnim vrstnim redom postopkov.
- Doslednost ali koherenca, pri kateri transakcija v zbirki podatkov ostaja stabilna, kar zahteva stalno spremljanje vseh operacij.
- Izolacija je pogoj in zagotovilo, da transakcije ne vplivajo druga na drugo, kar se običajno doseže z blokiranjem določenih funkcij, ki izolirajo podatke, vključene v transakcijo.
- Dolgotrajnost pomeni, da so vsi podatki v sistemu DBMS shranjeni dolgoročno, tudi po opravljeni transakciji, in tudi v primeru sesutja sistema, če pride do sesutja sistema DBMS. Za tega pogoja potrebni so zapisi transakcij, ki beležijo vse procese, ki potekajo.
Razvrstitev funkcij in zahtev
Podatkovna baza hrani informacije in jih skupaj z metapodatki povezuje v logično enoto, potrebno za obdelava. To je zelo uporabno orodje za upravljanje velikih datotek s preprosto poizvedbo, ki ima sistem dovoljenj, ki opredeljuje, kateri uporabniki ali programi imajo pravice dostopa.

Razvrstitev podatkovne zbirke:
Funkcija | Namen |
Shranjevanje podatkov | Besedila, dokumenti in gesla so shranjeni v zbirki podatkov. elektronsko, do podatkov je mogoče dostopati prek posvetovanja. |
Spreminjanje podatkov | Večina podatkovnih zbirk omogoča urejanje filtrov za zaščito podatkov, odvisno od tega, katera dovoljenja so na voljo. |
Čiščenje podatkov | Vnose v večini klasifikacij podatkovnih zbirk je mogoče popolnoma izbrisati, tako da ne nastanejo vrzeli. V nekaterih primerih je mogoče izbrisane podatke obnoviti, v drugih pa so trajno izbrisani. |
Upravljanje metapodatkov | Običajno so informacije shranjene z metapodatki ali metaznamkami, ki ohranjajo red v zbirki podatkov in omogočajo funkcijo iskanja. Metapodatki se pogosto uporabljajo tudi za urejanje dovoljenj. |
Varnost podatkov | Podatkovne zbirke morajo biti zaščitene, da se nepooblaščenim osebam prepreči dostop do podatkov, ki jih hranijo. |
Celovitost podatkov | Celovitost podatkov pomeni, da morajo biti skladni z določenimi zahtevami pravila za zagotavljanje njihove pravilnosti in opredelitev poslovne logike banke podatkov. |
Funkcija večnajemništva | Aplikacije podatkovne zbirke omogočajo dostop iz različnih naprav. Dodeljevanje dovoljenj in varnost podatkov sta pri večuporabniški uporabi osnovna. |
Optimizacija poizvedb | S tehničnega vidika mora biti podatkovna zbirka sposobna obdelati poizvedbe na najboljši možni način, da se zagotovi dobra delovanje. |
Sprožilci in shranjene procedure | Ta dva postopka sta mini aplikaciji, shranjeni v zbirki podatkov. Sprožilci in shranjene procedure so značilni postopki relacijskih podatkovnih zbirk. |
Preglednost sistema | Preglednost sistema je pomembna zlasti pri modelih razvrščanja porazdeljenih podatkovnih zbirk. |
Hierarhični model

Razlike med najpogostejše Modeli DB so rezultat tehničnega razvoja elektronskega prenosa podatkov, ki ni zasledoval le ciljev učinkovitosti in obvladljivosti, temveč je tudi razširil zmogljivosti najbolj znanih proizvajalcev. To je najstarejši model, ki je zdaj veliko boljši od relacijskega modela, čeprav je v zadnjem času vse bolj priljubljen.
XML uporablja ta sistem za shranjevanje informacije. Nekaj zavarovalnice in banke se v najstarejših aplikacijah sklicujejo na hierarhične zbirke podatkov. Najbolj znan je IBM IMS/DB.
V hierarhičnem modelu klasifikacije podatkov v podatkovni zbirki obstajajo stroge in nedvoumne odvisnosti. Vsak zapis ima samo eno prednost (razmerje med starši in otroki, PCR), razen korena, ki tvori drevesno shemo. Čeprav ima lahko vsako podrejeno vozlišče le eno starševsko vozlišče, imajo lahko "starši" poljubno število podrejenih vozlišč.
Pri strogi hierarhični razvrstitvi ravni, ki niso neposredno povezane, ne vplivajo druga na drugo, zato ni enostavno povezati dveh različnih dreves. Hkrati so hierarhične strukture podatkovnih zbirk izjemno prilagodljive in preproste. Zapisi z "otroci" se imenujejo zapisi, tisti brez njih pa listi in so običajno dokumenti v zapisu za liste v klasifikaciji podatkovne zbirke. Hierarhične poizvedbe po zbirki podatkov dosežejo liste, začnejo pri korenu in se pomikajo skozi različne zapise.
Grafično usmerjen DMS
Mrežni model se je razvijal skoraj sočasno z relacijskim modelom, čeprav so ga sčasoma premagali njegovi konkurenti. V nasprotju s hierarhičnim modelom zapisi tu ne razkrivajo strogih razmerij "starš - otrok", vendar ima lahko vsak od njih več kot enega precedensa, kar mu daje mrežno strukturo. Obstaja tudi edinstvena in nespremenljiva pot za dostop do zapisa.
V modelu omrežne podatkovne baze ni fiksne hierarhije, zato do istega cilja vodi več poti. Do zapisa, ki je osredotočen na sliko, je teoretično mogoče dostopati iz petih drugih zapisov, z dostopom do njega pa je mogoče dostopati do petih drugih zapisov.
Odvisnosti se lahko opredelijo tudi v modelu omrežja - zgornji register. Ni neposredno povezan z registrom na skrajnem desnem položaju, zato mora do njega priti prek registra na sredini, ki ga lahko sprejme ali zavrne. Lahko se obrnete na zgornji levi. V mrežnem modelu se zapisi dodajajo ali brišejo, ne da bi to vplivalo na globalno strukturo.
Danes se ta model uporablja v velikih računalnikih. Druga področja se še vedno zanašajo na hierarhični model ali pa uporabljajo relacijski model, ki je veliko bolj prilagodljiv in enostaven za uporabo. Nekateri znani modeli omrežnih podatkovnih zbirk so UDS Siemens in DMS Sperry Univac. Sčasoma sta oba ponudnika razvila tudi zanimive mešane oblike med omrežnim in relacijskim modelom. Grafična podatkovna baza z mrežasto strukturo velja za sodobno evolucijo mrežnega modela.

Skalabilnost shranjevanja
V dokumentno usmerjenem modelu podatkovne zbirke so dokumenti osnovna enota shranjevanja informacij. Te enote strukturirajo podatke in jih ne smemo zamenjevati s programskimi dokumenti za obdelavo besedila. Pri tem so podatki shranjeni v tako imenovanih parih "ključ - vrednost".
Ker nista določena niti struktura niti število parov, se lahko dokumenti, ki sestavljajo dokumentno usmerjeno zbirko podatkov, med seboj zelo razlikujejo. Vsak dokument je sam po sebi zaprta enota, zato povezav med dokumenti ni enostavno določiti.
V zadnjih letih so dokumentne zbirke podatkov zaradi uspeha NoSQL doživele velik razcvet, zlasti zaradi svoje dobre skalabilnosti. Primer sistema zbirke podatkov te vrste je MongoDB. V dokumentno usmerjenem modelu zbirke podatkov so podatki shranjeni v posameznih dokumentih in ne v tabelah kot v relacijskem modelu.
Ti sistemi so še posebej zanimivi za spletne aplikacije, saj omogočajo shranjevanje celotnih obrazcev HTML. Poudariti je treba, da so med različnimi dokumentnimi sistemi opazne razlike, od sintakse do notranje strukture, zato vse dokumentno usmerjene zbirke podatkov niso primerne za ta scenarij. Zaradi teh razlik obstaja več sistemov podatkovnih zbirk, usmerjenih v skladišča: Lotus Notes, Amazon SimpleDB, MongoDB, CouchDB, Riak, ThruDB in OrientDB.
Prednosti in slabosti

Ustrezni sistemi za upravljanje podatkovnih zbirk omogočajo boljši dostop do podatkov in optimizacijo upravljanja podatkov. Točkovni dostop pa pomaga končnim uporabnikom hitro in učinkovito deliti podatke kot del poslanstva organizacije.
Model zbirke podatkov | Leto nastanka | Prednosti | Slabosti |
Hierarhični | 1960-й | Zelo hiter bralni dostop, jasna struktura, tehnična preprostost. | Določena struktura v drevesu, ki ne omogoča povezav med drevesi. |
Omrežje | Začetek sedemdesetih let prejšnjega stoletja | Podpira na več načinov dostop do zapisov, brez stroge hierarhije. | Slaba vidljivost pri velikih podatkovnih bazah. |
Relativni | 1970-й | Enostavno, prilagodljivo ustvarjanje in urejanje, enostavna razširljivost, hitra uvedba v obratovanje, enostavna razširitev, hiter zagon, zelo dinamičen kontekst. | Neupravljivo pri velikih količinah podatkov, slaba segmentacija, umetni ključni atributi, zunanji programski vmesnik, slab odsev lastnosti in obnašanja predmetov. |
Objektno usmerjena | Konec osemdesetih let prejšnjega stoletja | boljša podpora za objektno usmerjene programske jezike, shranjevanje večpredstavnostnih vsebin. Podpira Objektno usmerjeni programski jeziki, Omogoča shranjevanje večpredstavnostne vsebine. | Manjša zmogljivost pri več podatkih, malo združljivih vmesnikov. |
Usmerjenost v dokumente | 1980-е | Ustrezni podatki so shranjeni centralno v neodvisnih dokumentih, prosta struktura, multimedijski koncept, se nanaša na klasifikacijo entitet podatkovne zbirke. | Organizacijsko delo je razmeroma zahtevno, pogosto zahteva programerske spretnosti. |
Aplikacije

Ljudje se tega morda ne zavedajo, vendar so podatkovne zbirke povsod. Ne glede na to, ali o njih kaj ve ali ne, je njihov vpliv na vsakdanje življenje ogromen. Podatkovne zbirke so odgovorne za številne storitve, ki jih ljudje uporabljajo vsak dan, od vremenskih aplikacij do spletnih filmov, in da bi se izognili zmedi zaradi povečane količine informacij, uporabljajo klasifikacijo podatkovnih zbirk.
aplikacije RDBMS:
- Bančništvo - za podatke o strankah, računih in posojilih ter bančnih transakcijah.
- Airlines, za rezervacije in informacije o voznem redu. Letalske družbe so bile med prvimi, ki so podatkovne zbirke uporabljale na geografsko porazdeljen način: terminali po vsem svetu so do centralnega sistema podatkovnih zbirk dostopali prek telefonskih linij in drugih omrežij za prenos podatkov.
- Univerze - za informacije o študentih, vpis predmetov in ocene.
- Transakcije s kreditnimi karticami - za nakupe s kreditnimi karticami in mesečne izpiske.
- Telekomunikacije - za vodenje evidence opravljenih klicev, izdelavo mesečnih računov, vzdrževanje stanj na predplačniških telefonskih karticah in shranjevanje informacij o komunikacijskih omrežjih.
- Finance - za shranjevanje informacij o zalogah, prodaji in nakupu finančnih instrumentov, kot so delnice in obveznice.
- prodaja - informacije o strankah, izdelkih in nakupih.
- Proizvodnja - za upravljanje dobavne verige in spremljanje proizvodnje v tovarnah, zalog v skladiščih, trgovinah in naročil blaga.
- Človeški viri - za informacije o zaposlenih, plačah, davkih na plače in ugodnostih.
prihodnji trendi

Svetovni splet (WWW ali krajše web) bo v prihodnjem pogledu na podatkovne zbirke še naprej pomemben vidik, tako kot sredstvo za objavljanje dokumentov kot sredstvo za izmenjavo informacij. WWW je eden od heterogene in kompleksna interakcijska okolja.
Nedavno so se pojavili tehnologija in standardi, ki omogočajo, da je omrežje skalabilna in upravljiva infrastruktura. Ena takšnih tehnologij je XML, ki se preoblikuje v spletni sistem podatkovnih baz v slogu tradicionalnih upravljavcev podatkovnih baz, ki daje veliko boljše rezultate kot iskalniki. Izziv je vključiti to funkcionalnost v XML in kar najbolje izkoristiti strateške informacije, ki jih lahko uporabnik najde na internetu.
Novi trendi so proaktivna in napovedna analiza zmogljivosti, testiranje obremenitve podatkovnih baz, uporaba NOSQL - mongodb in cassandra ter BigData (Hadoop) v podjetjih in oblačnih okoljih.
 Sistem jalta-potsdam: glavne značilnosti in faze razvoja
Sistem jalta-potsdam: glavne značilnosti in faze razvoja Finančni supermarket: poslovne značilnosti in razvojne možnosti
Finančni supermarket: poslovne značilnosti in razvojne možnosti Razvrstitev vgrajenih kuhinjskih nap: najboljši modeli, značilnosti, pregledi proizvajalcev
Razvrstitev vgrajenih kuhinjskih nap: najboljši modeli, značilnosti, pregledi proizvajalcev Prilagodljive strukture organizacijskega upravljanja: glavne vrste in njihove značilnosti
Prilagodljive strukture organizacijskega upravljanja: glavne vrste in njihove značilnosti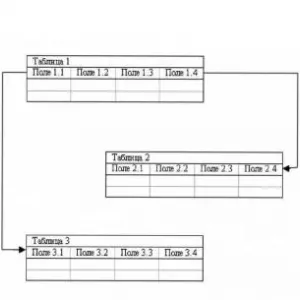 Relacijski podatkovni model je... Opredelitev, pojem, struktura in teorija normalizacije
Relacijski podatkovni model je... Opredelitev, pojem, struktura in teorija normalizacije Kompleksni sistem: značilnosti, struktura in metode opredelitve
Kompleksni sistem: značilnosti, struktura in metode opredelitve Objektno usmerjene podatkovne zbirke: koncept, osnovni koncepti, upravljanje, primeri
Objektno usmerjene podatkovne zbirke: koncept, osnovni koncepti, upravljanje, primeri Motorični spomin: klasifikacija, značilnosti, razvoj
Motorični spomin: klasifikacija, značilnosti, razvoj Oblika organizacije izobraževalnega procesa: osnovni pojmi, splošne značilnosti, klasifikacija
Oblika organizacije izobraževalnega procesa: osnovni pojmi, splošne značilnosti, klasifikacija